O que é arquitetura de software?
Aquilo que muitos falam mas poucos fazem
De vez em quando alguém menciona esse termo. Nos mais diversos contextos. É um termo que vem sendo usado para expressar muitas coisas diferentes, e quando um termo pode querer dizer qualquer coisa, ele acaba significando nenhuma delas. Nesse artigo explico a minha visão, depois de muito estudo, sobre o que é arquitetura de software, da forma mais precisa que consegui até então.

Also available in English
Todos nós, artesãos de software, escrevemos código da melhor forma que podemos, de acordo com os conhecimentos que temos de programação e também do domínio da aplicação em desenvolvimento.
Conforme passa o tempo vamos aprendendo mais e mais, tanto sobre técnicas de programação, quanto sobre as peculiares características do domínio da aplicação.
As tendências vão mudando, novas técnicas de programação vão sendo criadas e algumas vão ganhando mais força no mercado. O domínio da aplicação vai evoluindo e mudando conforme mais recursos são incorporados no software.
Então, o código que fizemos no passado parece que vai apodrecendo, porque tínhamos escrito ele sem os conhecimentos novos. Cada vez que olhamos o código antigo, mais temos a certeza de que aquele código não reflete mais a melhor modelagem para o problema que ele se propõe a resolver.

Isso é normal. Acontece desde o início de um projeto e vai continuar acontecendo até o fim. Software é soft porque foi feito para ser mudado. Refatorado. Experimentado. Ajustado. Corrigido. Incrementado.
Mas mudar esse código não é algo simples, porque os sistemas muitas vezes são complexos. O impacto de uma mudança nem sempre é claro. Bate o medo de quebrar algo. E é por isso que escrevemos testes automatizados. Para poder mudar o software sem medo. Para poder rescrever, alterar, experimentar, corrigir.

Não é só para saber se o software funciona. Se nunca fôssemos mudar aquele sistema, um teste manual bem feito garantiria muito bem que aquela versão funciona. Talvez garantiria até melhor do que testes automatizados, porque os testes manuais são obrigatoriamente end-to-end, e pegam também problemas imprevistos de domínio e de UX.
Mas acontece que escrever testes automatizados não é suficiente para podermos alterar facilmente nosso software. Se o código fica muito atrelado à detalhes de implementação, como tela, banco de dados, comunicação com outros sistemas, qualquer alteração no código está sujeita à modelagem intrínseca que esses fatores externos impõem ao nosso código.
Qualquer alteração de modelagem nas regras de negócio impõe alterações em múltiplos testes automatizados e nos detalhes de implementação. Melhorar o nome de uma variável na regra de negócio impõe que mude no banco também, ou na tela, ou em outros lugares. Mudanças maiores, estruturais, causam muito medo.

É por isso que foram criadas arquiteturas. Arquitetura não é uma receita de bolo para a modelagem de um sistema. Não é uma nomenclatura. Não é uma forma de organizar regras de negócio em classes ou métodos. Arquitetura não é DDD[1].
Arquiteturas são formas de isolar nosso código dos fatores externos, para que tenhamos a liberdade de modelar e remodelar a solução para o problema da forma que entendemos ser a melhor no momento. E depois remodelar de novo. E de novo.
Uma das arquiteturas mais famosas hoje em dia é a Clean Architecture:
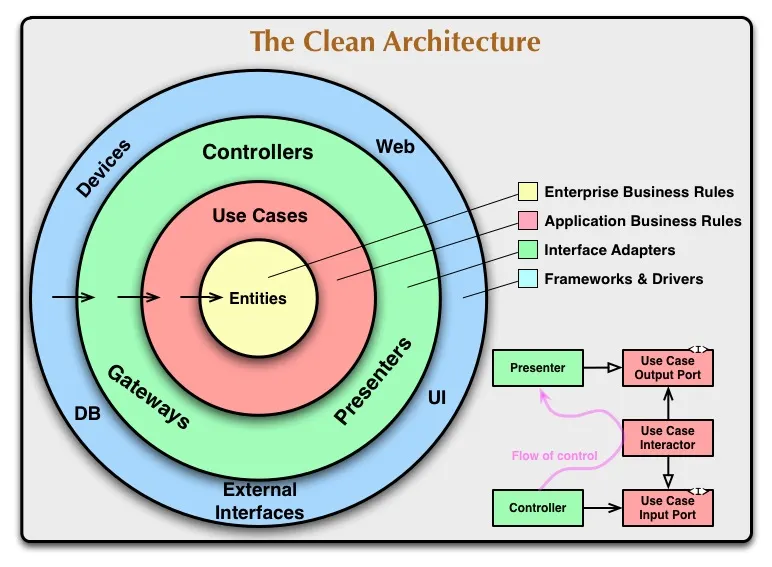
No artigo, Uncle Bob parece trazer justamente a receita de bolo, a nomenclatura e a forma de organizar em classes e métodos. Mas se você ler com atenção, vai notar que o objetivo - de todas as arquiteturas - é alcançar a tal independência, a tal liberdade.
Liberdade para aprender e remodelar o sistema sem quebrar tudo. Liberdade para limpar o código.
É por isso que existem Usecases (Interactors). Eles representam as ações que os usuários fazem no sistema. Eles são a ponte de comunicação entre a aplicação e a UI. É por isso também que existem Presenters, que fazem o caminho de volta da aplicação para a UI, quando for necessário um processamento extra dessas informações. Eles são parte da casca, que podem receber outros nomes e ter outras formas, desde que cumpram seu papel de isolar.
Daí para dentro, não devem ser impostas regras rígidas. O objetivo é justamente esse. Liberdade das regras impostas. Todos os testes que escrevemos, todos os Usecases e Presenters, existem para que tenhamos maior liberdade em definir como nossas Entities são e como vão se comportar.

Para que possamos nós mesmos definir se devem ser funções, classes, quantos métodos vão ter. Se vão ser instanciadas nos Gateways (Repositories), se vão receber dados no construtor ou nos métodos. E qualquer outra forma de modelagem.
Cada domínio tem a sua particularidade. As regras não cabem, os princípios sim. Cada princípio vai ser aplicado de uma forma em cada domínio. Tudo depende. Mas para isso precisamos nos acostumar novamente a pensar. Talvez voltar e fazer alguns katas ou dojos.
Esquece as regras, esquece os padrões… Qual a forma mais simples de resolver um problema?
Esquece a tela, esquece o banco… Qual o algoritmo mais simples para resolver aquele exercício da faculdade que o professor passou?
Esquece o Usecase, esquece a arquitetura… Escreve um teste, vê ele falhar, escreve o mínimo código possível para que ele passe, e depois refatora.
Esquece a classe, esquece a interface… Qual forma fica mais legível? Qual forma é mais simples de entender para o novato que acabou de entrar na empresa?
Esquece o padrão, esquece a herança… O pacote onde coloquei esse código está coerente? Ficou fácil para quem for usar essa regra encontrar onde ela está?
Claro que vamos fazer uso da tela, do banco, de Usecases e Patterns, de classes, interfaces e heranças. Mas essas coisas são ferramentas para nos ajudar a modelar o código mais simples possível para resolver o problema.
Cada parte do domínio tem um problema diferente. Por mais que pareça tudo o mesmo CRUD. Uma parte do sistema vai precisar de Entity com dados no construtor, outra parte vai precisar de Entity que nasce no Gateway. Uma parte vai precisar de um Gateway Burro[2], outra de um Gateway Espertinho[3]. Uma parte vai ter Usecase Miolo[4], outra vai ter tudo inline.
Mais importante é a pergunta: esse código está o mais simples possível para agora? Então segue o jogo, porque daqui a pouco vamos aprender mais e mudar esse código para algo melhor.

[1] O livro Domain Driven Design aborda alguns conceitos que colaboram no isolamento da aplicação dos fatores externos, mas o objetivo é modelar as regras de negócio de forma consistente com o domínio - o que é super importante, e assunto para outro artigo - e não foca tanto na independência.
[2] Gateway Burro é um termo criado pelo time de engenharia da Mercos para representar um Gateway (Repository) que simplesmente espelha a tabela do banco, sem nenhuma regra complexa adicional.
[3] Gateway Espertinho é outro termo criado pelo time de engenharia da Mercos para representar um Gateway (Repository) que tem uma diferença grande entre a interface que apresenta para o sistema e a tabela (ou as tabelas) que interage no banco, com regras adicionais de persistência, às vezes bem complexas.
[4] Usecase Miolo é mais um termo criado pelo time de engenharia da Mercos para representar um Usecase que representa uma ação lógica dentro do sistema, mas que nenhum usuário usa ele diretamente, é uma parte de regra compartilhada entre outros Usecases, mas que não parecia fazer sentido modelar como uma Entity.
